![]()
![]()

The Data Mining Laboratory (DMLab) uses the data mining technology it has developed to date as a base to construct sophisticated behavior forecast models and develop methods to extract customer characteristics using an experience-based approach.This system allows us to construct novel models of consumer behavior that are not bound by conventional theory.
The research base at the DMLab is original and highly developed, even on an international scale, and is particularly strong in application of character string analysis and graph mining to marketing. As a platform to fuse these techniques with purchase history data analysis, we employ the 'MUSASHI' as a system platform along with data mining algorithms, applications, and marketing theory, thereby allowing the Center to conduct fully comprehensive research.
Even at the international level, very few organizations working in the marketing area conduct research into analysis of in-store customer movement using stream data. The Data Mining Laboratory not only conducts research in this field, but also plays a pioneering role in research into advertising effect models that simultaneously handle upwards of 10,000 attributes.
As a result of critical acclaim on the international circuit and the Center's strong ties with industry, DMLab technology has now been introduced in over 100 firms, both in Japan and overseas. Data mining itself is now drawing ever more attention, having been showcased on a science program on Japanese television channel NHK.
The diagram below illustrates the research framework at the Data Mining Laboratory.
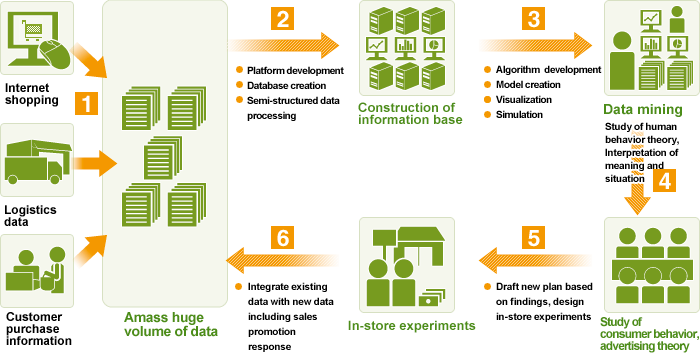
A vast amount of stream data on the behavior of one to two million consumers, including purchase information and customer information derived from Internet shopping history, POS systems, and point cards, is collected and compiled.
To establish a system capable of handling large-scale multidimensional data from transactions and sensor networks (stream data), a system platform based on calculating computers capable of large-scale data processing and adequate storage, MUSASHI, is developed and reviewed.
In the initial stage of investigation into methods and algorithms effective in data mining research of time-series models, character string analysis and graph mining are carried out, and then further new techniques and methods will be developed and implemented.
In addition to performing theory-based investigation into human behavior and data mining of semantic and circumstantial interpretation, a theoretical study is carried out with the researcher from Columbia University on marketing parameters that need to be controlled, as well as other factors. The Center hosts international workshops, determines theoretical frameworks, carries out and reviews small-scale pilot studies. Research is carried out applying such methods as Kalman filter and other time-series models developed in the field of statistical mathematics to multidimensional advertising data, and separation models that can handle streaming data are developed.
An advertising effect measurement model is constructed utilizing panel data for over 10,000 attributes pertinent to advertising, such as whether a given individual watches advertisements, and from this a framework for optimum asset allocation is developed. Principally by applying methods of combinatorial optimization, theoretical and experimental investigations are conducted into advertising effect modeling and optimum asset allocation.
On the basis of research findings, novel marketing strategies are chosen as a result of cooperation between industry and academia. Then, in order to validate the system in a real store, investigation is carried out on the introduction cost of RFID (Radio Frequency Identification), Wi-Fi terminals in stores around the country and required sensor precision. Next, technologies and methodologies are developed to analyze the streaming data on customer movement collected by RFID.
In the Kanto or Kansai region in Japan, store tests are conducted in which customer movement around a store is tracked using sensor networks. Experiments are designed in such a way that store information and other factors are controlled as much as possible, thereby allowing marketing variables to be handled effectively within the model. Data obtained from the tests is verified at the theoretical level, in-store layout of new products is optimized, and various approaches, including pricing strategies, are trialed.
The six step cycle above is repeated several times, with in-store tests from the second repetition onwards conducted in different regions and different chain stores, thereby permitting comparison on the basis of region and store. During the process of repetition, theories of the relationship between the in-store movement and purchase behavior of customers are developed, and a customer database that can be cheaply constructed and operated within a real company is developed along with the relevant know-how.
Finally, through proactive communication with the national manufacturing industries that play a critical role in in-store merchandising, a system of collaborative research is established between the world of industry and academia.Finally, through proactive communication and collaboration with the national retail stores that play a critical role in in-store merchandising, the Data Mining Laboratory strengthens its system of research and development.