![]()
![]()

データマイニング(Data Mining、データからの知識発掘)とは、大規模なデータベースから発見されたパターンやルールを知識ベースとして蓄積・学習し、新しい知識を発見・学習するプロセスです。また、データマイニングは、ナレッジ・ディスカバリー・イン・データベース(Knowledge Discovery in Database)、略してKDDと呼ばれることもあります。
大規模なデータベースを扱うためには、2つの重要な問題を解決する必要があります。第1の問題はデータの量的な問題であり、第2の問題はデータの質的な問題です。第1のデータの量的な問題とは、蓄積されている莫大なデータ量から生じる問題であり、それを処理するためには処理効率を向上させる技術的手法の開発が求められます。また、人間の能力では、そうした莫大なデータをすべて把握することはできないために、人間が認識できる何らかの表現形態を開発する必要もあります。
第2の問題であるデータの質的な問題とは、莫大なデータ内の属性、またはデータ間に複雑な関係が存在することから生じる問題です。属性間、またはデータ間でのパターンや規則性といっても、その関係が複雑なために組み合わせだけでも無限に近い組み合わせが存在することになります。それらすべてを検証していくことは不可能であるため、近似的に求め処理効率を向上させる方法などが必要になります。また、発見されたデータ間のパターンが複雑すぎると、人間がそこから意味を見つけだすことは困難になります。こうした意味でも、人間が認識でき、意味を付与することのできる表現形態を開発する必要があります。
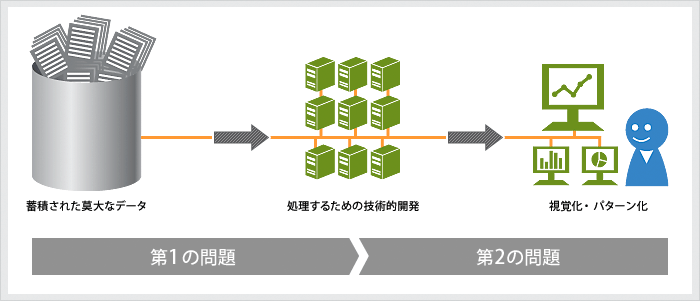
データマイニングは、大規模なデータベースを扱うことから生じる問題を解決するという課題を背負っています。つまり、データの規模や複雑性が大きくなることによって生じる処理効率や人間の認識力の限界などの問題をクリアすることが求められています。データマイニングにおける技術的アプローチとは、こうした大規模なデータベースを用いた分析における効率性と有効性の両者を達成しようとする技術的な方法を開発しようとするものです。
1.知識表現(Knowledge Representation)
知識表現とは、膨大で複雑なデータを人間が理解できるように、ある目的に基づいて特定のデータや手続きに変換する表現の枠組みを指します。データマイニングは、膨大なデータをある知識表現に変換し、そこから人間が意味を付与するプロセスであり、こうした知識表現を目的に応じて開発することがデータマイニングの重要な領域の1つとなります。例えば、決定木(decision tree)と呼ばれる知識表現があります。これは大量のデータ群を分類するとき、条件判断の結果を部分木として表し、データ群全体をツリー構造で表現する枠組みのことです。また、Fukuda, Morimoto, Morishita and Tokuyama (1996)は色を使ってデータの分布を表現し、大量データをビジュアライズ化することに成功しています。こうした知識表現は、結果的に人間のもつ知識をすなおに表現でき(安西,1989)、それをさらに発展させていけるものとして、知識の発見に重要な役割を担っています。
2.評価基準(Evaluation Criteria)
大量のデータの中から新しく、おもしろいパターンやルールを効率よく発見するためには、それを判断するための基準を設けなければなりません。データベースの中には膨大なパターンやルールが存在します。それらを人間が1つ1つ、あらゆる角度から評価していくことは実際には非常に難しく、簡易的な評価基準を設けてやることによって、そうした判断・評価を計算機に行わせることができます。そして、その結果がよいものだけを人間が判断・評価することによって、効率よく有益なパターンやルールを発見することが可能になります (Matheus, Chan, and Piatetsky-Shapiro,1993)。
評価基準の例として、結合ルール(Agrawal, Imielinski and Swami,1993)におけるコンフィデンスとサポートを取り上げてみます。結合ルール(association rule)とは、ある条件がAのとき、ある現象Bが起こることを指します。例えば、チーズバーガーとアップルパイを高い確率で購入する30代の女性は、オムツを100個以上買う人が多い、などのようなパターンやルールです。こうしたパターンやルールの確からしさを示すための評価基準にコンフィデンスとサポートがあります。コンフィデンス(confidence)とは、条件Aを満たすデータが現象Bを引き起こす割合を指し、コンフィデンスを見ることによって、そのパターンが起こる確からしさを評価することができます。しかし、条件Aを満たすデータが全体の内のわずかな部分にすぎないこともあり、確からしいパターンを発見しても、それがすぐに重要なパターンと考えることができません。サポート(support)とは全データにおいて、条件Aを満たす現象Bの占める割合を指しており、これによって発見されたパターンの全体に占める重要性を評価することができます。
3.アルゴリズム(Algorithms)
分析目的に合わせて効率よく処理するためのアルゴリズムの開発は不可欠であり、特に、大量データを扱う場合は、その重要性が大きくなります。例えば、2アイテム間の組み合わせを考える場合、10種類のアイテムでは、 10の二乗で組み合わせは100程度ですが、1000種類のアイテムになると、100万の組み合わせになり、3アイテム間の場合は、10億と数が増えれば増えるほど、組み合わせは指数的に増加します。大量データの計算処理効率の問題は、現実のビジネスの中でより重要な問題になると考えられます。
データマイニングの応用のためには、このように多様なアプローチが存在します。私たちは異なるバックグラウンドをもつ研究者がチームを組むことによって、より実践的で役に立つ大規模データの戦略的活用を提案したいと考えています。